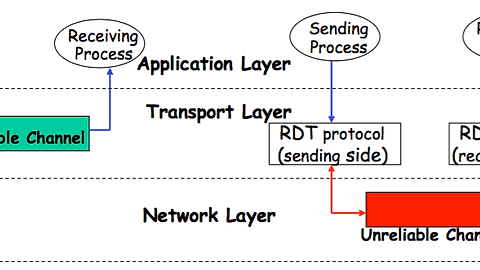
3.4.1 신뢰적인 데이터 전달 프로토콜의 구축
- 컴퓨터공학
- 2016. 3. 24. 13:54

3.4.1 신뢰적인 데이터 전달 프로토콜의 구축
신뢰적인 데이터 전송 프로토콜을 구축하기 위해서 가장 간단한 상황부터 시작해서 조금씩 더 복잡해지는 상황으로 이어지는 다음의 4가지 경우에 대해 알아봅시다.
- 완벽하게 신뢰적인 채널 상에서의 신뢰적인 데이터 전송 : rdt1.0
- 비트 오류가 있는 채널 상에서의 신뢰적인 데이터 전송 : rdt2.0
- rdt2.0의 수정된 버전 : rdt2.1, rdt2.2
- 비트 오류와 손실 있는 채널 상에서의 신뢰적인 데이터 전송 : rdt3.0

송신 측
rdt_send(data) 이벤트에 의해 상위 계층으로부터 데이터를 받습니다.
paket=make_pkt(data) 이벤트에 의해 데이터를 포함하는 패킷을 생성합니다.
udt_send(packet) 이벤트에 의해 패킷을 채널로 내려보내며 송신합니다.
수신 측
rdt_rcv(packet) 이벤트에 의해 하위 채널로부터 패킷을 수신합니다.
extract(packet,data) 이벤트에 의해 패킷으로부터 데이터를 추출합니다.
deliver_data(data) 이벤트에 의해 데이터를 상위 계층으로 전달합니다.
- 오류검출 : 체크섬 필드를 사용하여 비트오류 발생 시 수신자가 검출할 수 있게 합니다.
- 수신자 피드백 : 패킷이 정확하게 수신되었는지 아닌지를 수신자가 송신자에게 ACK 또는 NAK로 피드백 합니다.
- 재전송 : NAK의 피드백일 경우 송신자는 재전송합니다.

송신 측(2가지의 상태를 가집니다)
송신 측은 상위 계층으로부터 데이터가 전달되기를 기다립니다.
- rdt_send(data) 이벤트에 의해 상위 계층으로부터 데이터를 받으면, sndpkt=make_pkt(data,checksum) 이벤트에 의해 데이터와 체크섬을 포함하는 패킷을 생성하고, udt_send(sandpit) 이벤트에 의해 패킷을 채널로 내려보내며 송신합니다.
송신 후에는 오른쪽 상태로 넘어와 ACK 또는 NAK로 피드백 받기를 기다립니다.
만약, 수신 측이 잘 받고(receive) ACK의 피드백이 돌아온다면 왼쪽의 상태로 넘어가 상위계층으로부터 데이터가 전달되기를 기다리며 위의 과정을 반복합니다.
그러나, 수신 측이 잘 받았지만 NAK의 피드백이 돌아온다면 ACK의 피드백이 돌아올 때까지 udt_send(sandpit)의 과정을 반복합니다.
이 때 송신 측이 ACK 또는 NAK를 기다리는 오른쪽 상태에 있는 중에는 상위 계층으로부터 더 이상의 데이터를 전달받을 수 없습니다. rdt2.0은 전송-후-대기(Stop-and-Wait) 프로토콜이라고도 합니다.
- rdt_rcv(rcvpkt) 이벤트에 의해 하위 채널로부터 패킷을 수신합니다.
- corrupt(rcvpkt) 이벤트에 의해 수신한 패킷에 오류가 있는 경우 udt_send(NAK)로 NAK 피드백을 합니다.
- 수신한 패킷에 오류가 없는 경우 extract(rcvpkt, data) 이벤트에 의해 패킷으로부터 데이터를 추출합니다.
- deliver_data(data) 이벤트에 의해 데이터를 상위 계층으로 전달합니다.
- udt_send(ACK) 이벤트에 의해 ACK 피드백을 합니다.
 |  |
- 왼쪽 송신 측이 sequence number 0의 패킷을 보내면 0번에 대한 ACK/NAK를 기다립니다.
- 오른쪽 수신 측은 문제없이 잘 수신한 경우 ACK를 보내며 sequence number 1의 패킷이 수신되기를 기다립니다.
- 왼쪽 송신 측은 ACK를 받으면 sequence number 1의 패킷을 보내고, NAK를 받거나 피드백 패킷에 오류가 있을 경우에 sequence number 0의 패킷을 재전송합니다.
- 오른쪽 수신 측은 sequence number 1의 패킷을 기다리고 있는데, sequence number 1의 패킷이 수신되면 순조롭게 ACK를 보내면 되고, sequence number 0의 패킷이 도착한다면 sequence number 0의 패킷이 중복도착했으므로 무언가 중간에 문제가 생겼음을 알고 sequence number 0에 대한 ACK를 보냅니다.
기능은 rdt2.1과 동일하지만 NAK를 사용하지 않고(NAK-free) ACK만 사용하는 모델이 rdt2.2입니다.
NAK를 보내는 대신에, 가장 최근에 잘 받은 패킷에 대한 ACK를 보냄으로써 NAK를 보내는 것과 동일한 효과를 얻을 수 있습니다. 다음 그림을 보면 쉽게 이해할 수 있습니다.

송신 측이 pkt1을 보냈지만 수신측이 ACK1이 아닌 ACK0만 계속 보낸다면 송신 측은 pkt1의 전송에 문제가 생겼음을 인식하고 재전송할 수 있다라는 의미입니다.
 |  |
타이머는 패킷 손실이 일어났다는 100% 보장은 아니지만, 손실이 일어났을 만한 그런시간을 현명하게 선택하는 방식입니다. 만일 ACK가 이 시간안에 수신되지 않는다면 패킷은 재전송될 것(그림 b,c)입니다. 심지어 패킷이 유별나게 큰 delay를 가져서 타이머 시간보다 늦게 도착하는 경우 비록 ACK가 손실되지 않았다 하더라도 패킷은 재전송할 수 있습니다. 이는 중복 데이터 패킷(duplicate data packet)의 가능성을 포함한다는 이야기입니다.(그림d) 다행히 rdt2.2는 이미 패킷이 중복되었을 경우를 처리하기 위한 sequence number의 기능을 가지고 있습니다.
재밌는 점은 프로토콜 rdt3.0은 기능적으로 매우 정확한 프로토콜임에도 불구하고 오늘날의 고속 네트워크에서 만족스러운 성능을 보여주지 못한다는 점입니다. 이유는 '전송-후-대기(Stop-and-Wait)'방식이기 때문입니다.
예를 들어 봅시다. 미국 서부에서 동부로 통신하는 경우를 고려합시다.
- 두 종단 사이의 RTT = 30msec
- 1Gbps(초당 10의 9승 bit) 전송률(R)을 가진 채널에 의해서 연결
- 헤더와 데이터를 포함하여 패킷당 1000byte(8000bit)의 패킷크기(L)의 패킷을 전송
RTT : Round Trip Time; 패킷이 송신측에서 수신측으로 전송되고,ACK가 수신측에서 송신측으로 돌아오는데 걸리는 시간
위와 같은 가정된 상황에서 8000비트를 실제로 보내는데 필요한 시간은 다음과 같습니다.

즉, 8usec동안 송신측은 8000비트의 첫 비트부터 마지막 비트까지 수신측으로 보냈습니다. 보낸 패킷들은 15msec동안 서부에서 동부로 이동하며 수신측에게 도착할 것이며, 수신 측이 ACK를 바로 보낸다는 가정하에 또 다른 15msec후에 ACK가 송신측으로 도착할 것입니다. 결국 송신 측은 30.008msec 후에 ACK를 받았습니다.

그러므로 30.008msec 동안 송신 측은 단지 0.008msec동안만 데이터를 전송한 셈입니다. 이용률로 따져보자면 다음과 같이 아주 형편없음을 알 수 있습니다.

즉, 송신자는 전체 시간의 0.00027만큼만 바빴던 것입니다. 어이가 없죠. 이것이 바로 stop-and-wait 프로토콜의 문제점이라는 것입니다. 그런데 아주 간단한 해결책이 있습니다. ACK를 기다리지 말고, 여러 패킷을 전송하도록 허용하는 것입니다.

패킷을 파이프라인에 채워넣음으로써 이용률은 3배가 될 수 있습니다. 이 기술을 파이프라이닝(pipelining)이라고 하며, 다음과 같은 사항들을 고려해야 합니다.
- sequence number 범위의 증가 : 여러 패킷을 보낼 수 있게 됨으로써 0과 1로만은 부족해집니다.
- 버퍼의 필요 : 송신 측과 수신 측은 여러 패킷 이상을 담을 수 있는 버퍼가 필요해졌습니다.
- 파이프라인 오류 회복 방법 : 파이프라인에서 패킷 손실과 지연 패킷에 대한 처리방식이 필요해졌습니다.
이렇게 최종적으로 파이프라이닝 기술까지 오면서 위의 3가지 고려사항이 중요해졌습니다. 그래서 2가지 기본적인 접근방법인 GBN(Go-Back-N, N부터 반복)과 SR(Selective Repeat,선택적 반복) 프로토콜이 나타나게 되었습니다.
'컴퓨터공학' 카테고리의 다른 글
| MMT(MPEG Media Transport) 소개 (0) | 2016.03.26 |
|---|---|
| MPEG-DASH 소개 (1) | 2016.03.26 |
| 3.4 신뢰성 있는 데이터 전송의 원리 (0) | 2016.03.23 |
| 7.4 부가설명 (2) RTP, RTCP, RTSP 간략히 요약 비교 (0) | 2016.03.21 |
| 7.4 부가설명 (1) RSTP (0) | 2016.03.21 |